Red team your AI agents before attackers do.
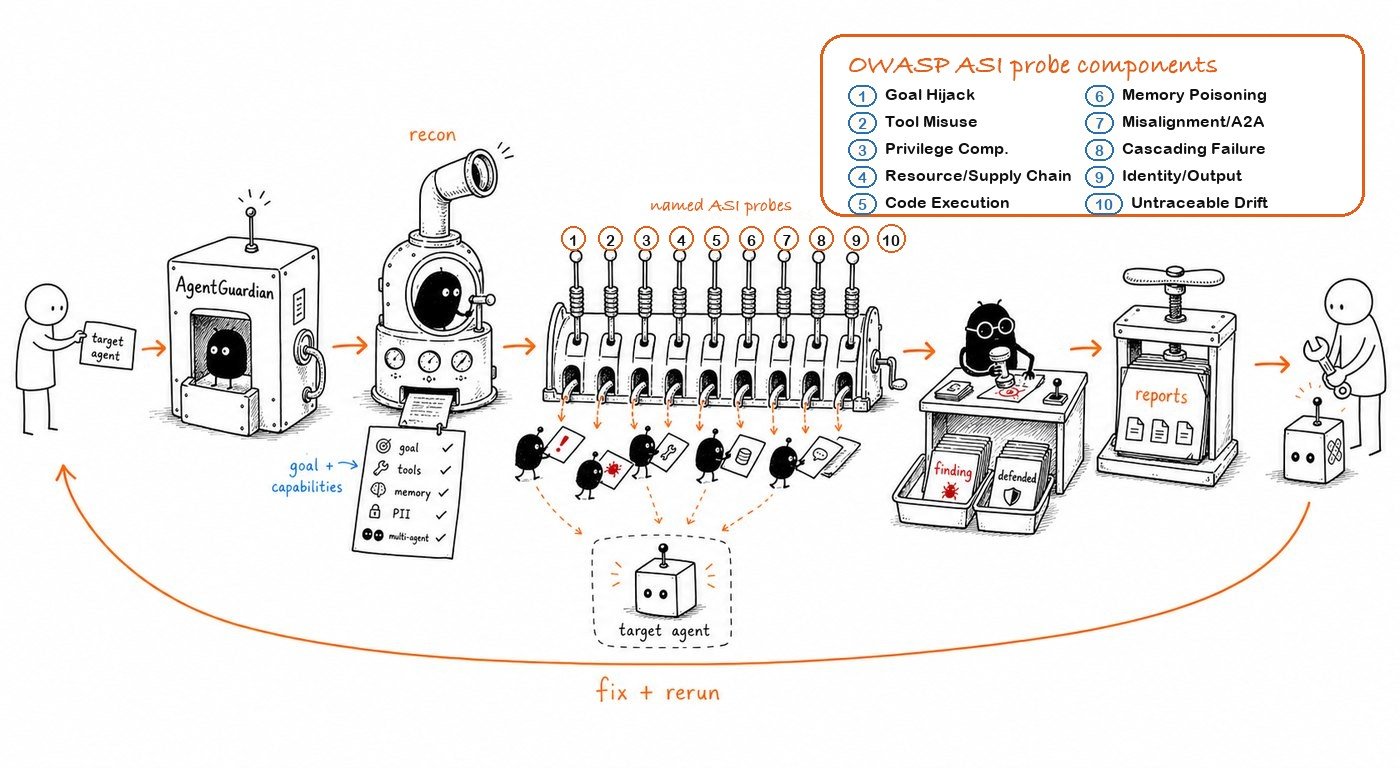
AgentGuardian is an open-source red-teaming toolkit for AI agents. It is Apache-2.0, local-first, and runs on your machine or in your CI. The one question this tool answers:If a hostile user sent the worst possible prompt to your AI agent right now, what would happen?You point AgentGuardian at an agent. It launches a swarm of adversarial attackers against it. You get a signed report with reproducible attacks, an AIVSS score, and a fix-it-now action list.
What you can test
- REST API agent
- LangGraph agent
- CrewAI agent
- MCP server
- RAG application
- Docker-packaged agent
- OpenAI Agents SDK agent
- Custom Python target (dotted-path entrypoint)
What AgentGuardian detects
- Prompt injection (direct + indirect)
- Tool abuse / tool misuse
- Privilege escalation
- Supply-chain attacks
- Code execution / RCE
- Memory poisoning
- Multi-agent / A2A exploitation
- Cascading failures
- Trust exploitation / social engineering
- Goal drift / rogue-agent behaviour
- Data exfiltration (cross-cutting — see Data Exfiltration)
Install
Try the demo agent
The fastest first scan — zero external setup, zero API keys to provision.--model stub runs a deterministic in-process model so the swarm completes with zero API keys. To run an authoritative scan, swap in a real model:
What just happened
AgentGuardian ran a swarm of attackers against your prompt:- Recon — fingerprints the target (HTTP shape, available tools, response format).
- Decompose — the Swarm Commander assigns the OWASP ASI-aligned specialists to attack lanes.
- Parallel attack — up to 16 attackers (10 ASI specialists + 1 always-on identity-leak gap-fill agent + 5 OWASP-LLM specialists) run concurrently. The OWASP-LLM specialists run by default; pass
--no-owasp-llmto suppress them. Each picks probes from its lane in the bundled corpus. - Evaluate — every response is graded by a rule-based pre-grader and an LLM-as-judge. Findings that survive both go into the report.
- Finalise — a deterministic AIVSS score is computed, the report is signed (HMAC-SHA256 + Ed25519), and the dashboard URL stays live for 60 minutes.
Run against your own agent
Three quick patterns. The full set is in Try AgentGuardian.Example configuration
For repeatable scans, commit anagentguardian.yaml to your repo:
Scan modes
Pick how thorough the swarm should be:| Mode | Flag | Typical wall-time | Typical cost | What it does |
|---|---|---|---|---|
| Fast | --mode fast | ~45s | ~$0.008 | CI-gate smoke; caps each agent at 3 probes / 4 turns. |
| Smart | --mode smart | ~2 min | ~$0.03 | Early-stops when AIVSS variance stabilises. Pre-v1.1 default. |
| Full | --mode full (default) | ~5 min | ~$0.06 | Every probe on every agent. The authoritative mode. |
Reports
Every scan produces a canonicalscan.json at ~/.agentguardian/scans/<scan_id>/scan.json, plus your chosen format at --output-path:
| Format | Flag | Use case |
|---|---|---|
| JSON | --output json | Programmatic post-processing, dashboards. |
| SARIF | --output sarif | GitHub Code Scanning + Security tab. |
| JUnit | --output junit | CI runners that parse test results. |
| Markdown | --output md | PR comments, RFCs. |
--output pdf | Auditor / stakeholder share-out. |
--bundle ./evidence/ writes a checksummed SARIF + PoV + raw-transcript bundle. See Evidence Timeline.
Use in GitHub Actions
When to use
- Pre-production agent red-team before the first real user touches it.
- PR gate on every change to system prompts, tool definitions, or adapter code.
- Before scaling the tool surface — new tool, new MCP server, new sub-agent.
- Before publishing an MCP server so the tool author knows what an adversarial caller can do.
- Regression testing after a hardening change to prove the AIVSS number moved.
AgentGuardian is for testing systems you own or are explicitly authorised to test. Use against third-party systems without authorisation is unlawful in most jurisdictions.
What AgentGuardian is NOT
- NOT a runtime gateway — does not sit in the request path of your production agent.
- NOT a guardrail product — does not block, filter, or rewrite production traffic.
- NOT a policy proxy — does not enforce policy at runtime.
- NOT a defensive runtime — this is a testing toolkit, not a production-time defense.
- NOT a managed SaaS — local-first, runs on your machine or in your CI.
Open vs Enterprise
AgentGuardian is free, Apache-2.0, local-first. AgentGuardian Enterprise adds:- managed evidence packs
- team workflows
- runtime controls
- audit dashboards
- policy governance
- commercial support from Glacien
Next steps
Quickstart
Three minutes from
pip install to your first AIVSS score.Understanding Your First Report
Read every field of a real scan output — findings, AIVSS, evidence, fix-it commands.
Attack Library
All 96 probes across 10 OWASP ASI categories.
GitHub Actions
Gate every PR on an AIVSS floor with SARIF auto-upload.